Essential NLP Guide for data scientists
Introduction
Organizations today deal with huge amount and wide variety of data – calls from customers, their emails, tweets, data from mobile applications and what not.
It takes a lot of effort and time to make this data useful.
One of the core skills in extracting information from text data is Natural Language Processing (NLP).
1. Stemming
. What is Stemming?: Stemming 来源 is the process of reducing the words(generally modified or derived) to their word stem or root form.
. Implementation: Here is how you can stem a word using the Porter2 algorithm from the . stemming library.
#!pip install stemming
from stemming.porter2 import stem
stem("casually")
2. Lemmatisation
. What is Lemmatisation?: Lemmatisation 词形还原 is the process of reducing a group of words into their lemma or dictionary form.
It takes into account things like POS(Parts of Speech), the meaning of the word in the sentence, the meaning of the word in the nearby sentences etc.
before reducing the word to its lemma.
. Implementation: Below is an implementation of an English Lemmatiser using spacy.
#!pip install spacy
#python -m spacy download en
import spacy
nlp=spacy.load("en")
doc="good better best"
for token in nlp(doc):
print(token,token.lemma_)
3. Word Embeddings
. What is Word Embeddings?: Word Embeddings is the name of the techniques which are used to represent Natural Language in vector form of real numbers.
They are useful because of computers’ inability to process Natural Language.
So these Word Embeddings capture the essence and relationship between words in a Natural Language using real numbers.
In Word Embeddings, a word or a phrase is represented in a fixed dimension vector of length say 100.
So for example-
A word “man” might be represented in a 5-dimension vector as
 where each of these numbers is the magnitude of the word in a particular direction.
where each of these numbers is the magnitude of the word in a particular direction.
 . Implementation: Here is how you can obtain pre-trained Word Vector of a word using the gensim package.
Download the Google News pre-trained Word Vectors from here.
. Implementation: Here is how you can obtain pre-trained Word Vector of a word using the gensim package.
Download the Google News pre-trained Word Vectors from here.
#!pip install gensim
from gensim.models.keyedvectors import KeyedVectors
word_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)
word_vectors['human']
. Implementation: Here is how you can train your own word vectors using gensim
sentence=[['first','sentence'],['second','sentence']]
model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Part-Of-Speech Tagging
. What is Part-Of-Speech Tagging?: In Simplistic terms, Part-Of-Speech Tagging is the process of marking up of words in a sentence as nouns, verbs, adjectives, adverbs etc.
For example, in the sentence-
“Ashok killed the snake with a stick”
The Parts-Of-Speech are identified as –
Ashok PROPN
killed VERB
the DET
snake NOUN
with ADP
a DET
stick NOUN
.
PUNCT
. Paper 1: This paper by choi aptly titled The Last Gist to the State-of-the-Art presents a novel method called Dynamic Feature Induction which achieves state-of-the-art on POS Tagging task
. Paper 2: This paper presents performing unsupervised POS Tagging using Anchor Hidden Markov Models.
. Implementation: Here is how we can perform POS Tagging using spacy.
#!pip install spacy
#!python -m spacy download en
nlp=spacy.load('en')
sentence="Ashok killed the snake with a stick"
for token in nlp(sentence):
print(token,token.pos_)
5. Named Entity Disambiguation
. What is Named Entity Disambiguation?: Named Entity Disambiguation is the process of identifying the mentions of entities in a sentence.
For example, in the sentence-
“Apple earned a revenue of 200 Billion USD in 2016”
It is the task of Named Entity Disambiguation to infer that Apple in the sentence is the company Apple and not a fruit.
Named Entity, in general, requires a knowledge base of entities which it can use to link entities in the sentence to the knowledge base.
. Paper 1: This paper by Huang makes use of Deep Semantic Relatedness models based on Deep Neural Networks along with Knowledgebase to achieve a state-of-the-art result on Named Entity Disambiguation.
. Paper 2: This paper by Ganea and Hofmann make use of Local Neural Attention along with Word Embeddings and no manually crafted features.
6. Named Entity Recognition
. What is Named Entity Recognition?: Named Entity Recognition is the task of identifying entities in a sentence and classifying them into categories like a person, organisation, date, location, time etc.
For example, a NER would take in a sentence like –
“Ram of Apple Inc.
travelled to Sydney on 5th October 2017”
and return something like
Ram
of
Apple ORG
Inc.
ORG
travelled
to
Sydney GPE
on
5th DATE
October DATE
2017 DATE
Here, ORG stands for Organisation and GPE stands for location.
The problem with current NERs is that even state-of-the-art NER tend to perform poorly when they are used on a domain of data which is different from the data, the NER was trained on.
 . Paper: This excellent paper makes use of bi-directional LSTMs and combines Supervised and Unsupervised learning methods to achieve a state-of-the-art result in Named Entity Recognition in 4 languages.
. Implementation: Here is how you can perform Named Entity Recognition using spacy.
. Paper: This excellent paper makes use of bi-directional LSTMs and combines Supervised and Unsupervised learning methods to achieve a state-of-the-art result in Named Entity Recognition in 4 languages.
. Implementation: Here is how you can perform Named Entity Recognition using spacy.
import spacy
nlp=spacy.load('en')sentence="Ram of Apple Inc.
travelled to Sydney on 5th October 2017"
for token in nlp(sentence):
print(token, token.ent_type_)
7. Sentiment Analysis
. What is Sentiment Analysis?: Sentiment Analysis is a broad range of subjective analysis which uses Natural Language processing techniques to perform tasks such as identifying the sentiment of a customer review, positive or negative feeling in a sentence, judging mood via voice analysis or written text analysis etc.
For example-
“I did not like the chocolate ice-cream” – is a negative experience of ice-cream.
“I did not hate the chocolate ice-cream” – may be considered as a neutral experience
There is a wide range of methods which are used to perform sentiment analysis starting from taking a count of negative and positive words in a sentence to using LSTMs with Word Embeddings.
. Blog 1: This article focuses on performing sentiment analysis on movie tweets
. Blog 2: This article focuses on performing sentiment analysis of tweets during the Chennai flood.
. Paper 1: This paper takes the Supervised Learning method approach with Naive Bayes method to classify IMDB reviews.
. Paper 2: This paper makes use of Unsupervised Learning method with LDA to identify aspects and sentiments of user-generated reviews.
This paper is outstanding in the sense that it addresses the problem of shortage of annotated reviews.
. Repository: This is an awesome repository of the research papers and implementation of sentiment analysis in various languages.
. Dataset 1: Multi-Domain sentiment dataset version 2.0
. Dataset 2: Twitter Sentiment analysis Dataset
. Competition: A very good competition where you can check the performance of your models on the sentiment analysis task of movie reviews of rotten tomatoes.
8. Semantic Text Similarity
. What is Semantic Text Similarity?: Semantic Text Similarity is the process of analysing similarity between two pieces of text with respect to the meaning and essence of the text rather than analysing the syntax of the two pieces of text.
Also, similarity is different than relatedness.
For example –
Car and Bus are similar but Car and fuel are related.
. Paper 1: This paper presents the different approaches to measuring text similarity in detail.
A must read paper to know about the existing approaches at a single place.
. Paper 2: This paper introduces CNNs to rank a pair of two short texts
. Paper 3: This paper makes use of Tree-LSTMs which achieve a state-of-the-art result on Semantic Relatedness of texts and Semantic Classification.
9. Language Identification
. What is Language Identification?: Language identification is the task of identifying the language in which the content is in.
It makes use of statistical as well as syntactical properties of the language to perform this task.
It may also be considered as a special case of text classification.
. Blog: In this blog post by fastText, they introduce a new tool which can identify 170 languages under 1MB of memory usage.
. Paper 1: This paper discusses 7 methods of language identification of 285 languages.
. Paper 2: This paper describes how Deep Neural Networks can be used to achieve state-of-the-art results on Automatic Language Identification.
10. Text Summarisation
. What is Text Summarisation?: Text Summarisation is the process of shortening up of a text by identifying the important points of the text and creating a summary using these points.
The goal of Text Summarisation is to retain maximum information along with maximum shortening of text without altering the meaning of the text.
Paper 1: This paper describes a Neural Attention Model based approach for Abstractive Sentence Summarization.
Paper 2: This paper describes how sequence-to-sequence RNNs can be used to achieve state-of-the-art results on Text Summarisation.
Repository: This repository by Google Brain team has the codes for using a sequence-to-sequence model customised for Text Summarisation.
The model is trained on Gigaword dataset.
Application: Reddit’s autotldr bot uses Text Summarisation to summarise articles into the comments of a post.
This feature turned out to be very famous amongst the Reddit users.
Implementation: Here is how you can quickly summarise your text using the gensim package.
from gensim.summarization import summarize
sentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document.
Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining.
The main idea of summarization is to find a subset of data which contains the information of the entire set.
Such techniques are widely used in industry today.
Search engines are an example; others include summarization of documents, image collections and videos.
Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e.
salient) images.
For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction.
Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary.
In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express.
Such a summary might include verbal innovations.
Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."
summarize(sentence)
NLP 自然语言处理学习总结
3 常用中文分词?
中文文本词与词之间没有像英文那样有空格分隔,因此很多时候中文文本操作都涉及切词,这里整理了一些中文分词工具。
StanfordNLP(直接使用CRF 的方法,特征窗口为5。)汉语分词工具(个人推荐)
哈工大语言云
庖丁解牛分词
盘古分词 ICTCLAS(中科院)汉语词法分析系统
IKAnalyzer(Luence项目下,基于java的)
FudanNLP(复旦大学)
4 词性标注方法?句法分析方法?
原理描述:标注一篇文章中的句子,即语句标注,使用标注方法BIO标注。
则观察序列X就是一个语料库(此处假设一篇文章,x代表文章中的每一句,X是x的集合),标识序列Y是BIO,即对应X序列的识别,从而可以根据条件概率P(标注|句子),推测出正确的句子标注。
显然,这里针对的是序列状态,即CRF是用来标注或划分序列结构数据的概率化结构模型,CRF可以看作无向图模型或者马尔科夫随机场。
用过CRF的都知道,CRF是一个序列标注模型,指的是把一个词序列的每个词打上一个标记。
一般通过,在词的左右开一个小窗口,根据窗口里面的词,和待标注词语来实现特征模板的提取。
最后通过特征的组合决定需要打的tag是什么。
5 命名实体识别?三种主流算法,CRF,字典法和混合方法
1 CRF:在CRF for Chinese NER这个任务中,提取的特征大多是该词是否为中国人名姓氏用字,该词是否为中国人名名字用字之类的,True or false的特征。
所以一个可靠的百家姓的表就十分重要啦~在国内学者做的诸多实验中,效果最好的人名可以F1测度达到90%,最差的机构名达到85%。
2 字典法:在NER中就是把每个字都当开头的字放到trie-tree中查一遍,查到了就是NE。
中文的trie-tree需要进行哈希,因为中文字符太多了,不像英文就26个。
3 对六类不同的命名实体采取不一样的手段进行处理,例如对于人名,进行字级别的条件概率计算。
中文:哈工大(语言云)上海交大 英文:stanfordNER等
6 基于主动学习的中医文献句法识别研究
. 6.1 语料库知识?
语料库作为一个或者多个应用目标而专门收集的,有一定结构的、有代表的、可被计算机程序检索的、具有一定规模的语料的集合。
语料库划分:① 时间划分② 加工深度划分:标注语料库和非标注语料库③ 结构划分⑤ 语种划分⑥ 动态更新程度划分:参考语料库和监控语料库
语料库构建原则:① 代表性② 结构性③ 平衡性④ 规模性⑤ 元数据:元数据对
语料标注的优缺点
① 优点: 研究方便。
可重用、功能多样性、分析清晰。
② 缺点: 语料不客观(手工标注准确率高而一致性差,自动或者半自动标注一致性高而准确率差)、标注不一致、准确率低
. 6.2 条件随机场解决标注问题?
条件随机场用于序列标注,中文分词、中文人名识别和歧义消解等自然语言处理中,表现出很好的效果。
原理是:对给定的观察序列和标注序列,建立条件概率模型。
条件随机场可用于不同预测问题,其学习方法通常是极大似然估计。
我爱中国,进行序列标注案例讲解条件随机场。
(规则模型和统计模型问题)
条件随机场模型也需要解决三个基本问题:特征的选择(表示第i个观察值为“爱”时,相对yi,yi-1的标记分别是B,I),参数训练和解码。
. 6.3 隐马尔可夫模型
应用:词类标注、语音识别、局部句法剖析、语块分析、命名实体识别、信息抽取等。
应用于自然科学、工程技术、生物科技、公用事业、信道编码等多个领域。
马尔可夫链:在随机过程中,每个语言符号的出现概率不相互独立,每个随机试验的当前状态依赖于此前状态,这种链就是马尔可夫链。
多元马尔科夫链:考虑前一个语言符号对后一个语言符号出现概率的影响,这样得出的语言成分的链叫做一重马尔可夫链,也是二元语法。
二重马尔可夫链,也是三元语法,三重马尔可夫链,也是四元语法
. 隐马尔可夫模型思想的三个问题
问题1(似然度问题):给一个HMM λ=(A,B) 和一个观察序列O,确定观察序列的似然度问题 P(O|λ) 。
(向前算法解决)
问题2(解码问题):给定一个观察序列O和一个HMM λ=(A,B),找出最好的隐藏状态序列Q。
(维特比算法解决)
问题3(学习问题):给定一个观察序列O和一个HMM中的状态集合,自动学习HMM的参数A和B。
(向前向后算法解决)
. 6.4 Viterbi算法解码
思路:
1 计算时间步1的维特比概率
2 计算时间步2的维特比概率,在(1) 基础计算
3 计算时间步3的维特比概率,在(2) 基础计算
4 维特比反向追踪路径
维特比算法与向前算法的区别:
(1)维特比算法要在前面路径的概率中选择最大值,而向前算法则计算其总和,除此之外,维特比算法和向前算法一样。
(2)维特比算法有反向指针,寻找隐藏状态路径,而向前算法没有反向指针。
HMM和维特比算法解决随机词类标注问题,利用Viterbi算法的中文句法标注
. 6.5 序列标注方法 参照上面词性标注
. 6.6 模型评价方法
模型:方法=模型+策略+算法
模型问题涉及:训练误差、测试误差、过拟合等问题。
通常将学习方法对未知数据的预测能力称为泛化能力。
模型评价参数:
准确率P=识别正确的数量/全部识别出的数量
错误率 =识别错误的数量/全部识别出的数量
精度=识别正确正的数量/识别正确的数量
召回率R=识别正确的数量/全部正确的总量(识别出+识别不出的)
F度量=2PR/(P+R)
数据正负均衡适合准确率 数据不均适合召回率,精度,F度量
几种模型评估的方法:
K-折交叉验证、随机二次抽样评估等 ROC曲线评价两个模型好坏
7 基于文本处理技术的研究生英语等级考试词汇表构建系统
完成对2002--2010年17套GET真题的核心单词抽取。
其中包括数据清洗,停用词处理,分词,词频统计,排序等常用方法。
真题算是结构化数据,有一定规则,比较容易处理。
此过程其实就是数据清洗过程)最后把所有单词集中汇总,再去除如:a/an/of/on/frist等停用词(中文文本处理也需要对停用词处理,诸如:的,地,是等)。
处理好的单词进行去重和词频统计,最后再利用网络工具对英语翻译。
然后根据词频排序。
. 7.1 Apache Tika?
Apache Tika内容抽取工具,其强大之处在于可以处理各种文件,另外节约您更多的时间用来做重要的事情。
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件
Tika的功能:•文档类型检测 •内容提取 •元数据提取 •语言检测
. 7.2 文本词频统计?词频排序方法?
算法思想:
1 历年(2002—2010年)GET考试真题,文档格式不一。
网上收集
2 对所有格式不一的文档进行统计处理成txt文档,格式化(去除汉字/标点/空格等非英文单词)和去除停用词(去除891个停用词)处理。
3 对清洗后的单词进行去重和词频统计,通过Map统计词频,实体存储:单词-词频。
(数组也可以,只是面对特别大的数据,数组存在越界问题)。
排序:根据词频或者字母
4 提取核心词汇,大于5的和小于25次的数据,可以自己制定阈值。
遍历list<实体>列表时候,通过获取实体的词频属性控制选取词汇表尺寸。
5 最后一步,中英文翻译。
8 朴素贝叶斯模型的文本分类器的设计与实现
. 8.1 朴素贝叶斯公式
0:喜悦 1:愤怒 2:厌恶 3:低落
. 8.2 朴素贝叶斯原理
-->训练文本预处理,构造分类器。
(即对贝叶斯公式实现文本分类参数值的求解,暂时不理解没关系,下文详解)
-->构造预测分类函数
-->对测试数据预处理
-->使用分类器分类
对于一个新的训练文档d,究竟属于如上四个类别的哪个类别?我们可以根据贝叶斯公式,只是此刻变化成具体的对象。
> P( Category | Document):测试文档属于某类的概率
> P( Category)):从文档空间中随机抽取一个文档d,它属于类别c的概率。
(某类文档数目/总文档数目)
> (P ( Document | Category ):文档d对于给定类c的概率(某类下文档中单词数/某类中总的单词数)
> P(Document):从文档空间中随机抽取一个文档d的概率(对于每个类别都一样,可以忽略不计算。
此时为求最大似然概率)
> C(d)=argmax {P(C_i)*P(d|c_i)}:求出近似的贝叶斯每个类别的概率,比较获取最大的概率,此时文档归为最大概率的一类,分类成功。
. 综述
1. 事先收集处理数据集(涉及网络爬虫和中文切词,特征选取)
2. 预处理:(去掉停用词,移除频数过小的词汇【根据具体情况】)
3. 实验过程:
数据集分两部分(3:7):30%作为测试集,70%作为训练集
增加置信度:10-折交叉验证(整个数据集分为10等份,9份合并为训练集,余下1份作为测试集。
一共运行10遍,取平均值作为分类结果)优缺点对比分析
4. 评价标准:
宏评价&微评价
平滑因子
. 8.3 生产模型与判别模型区别
1)生产式模型:直接对联合分布进行建模,如:隐马尔科夫模型、马尔科夫随机场等
2)判别式模型:对条件分布进行建模,如:条件随机场、支持向量机、逻辑回归等。
生成模型优点:1)由联合分布2)收敛速度比较快。
3)能够应付隐变量。
缺点:为了估算准确,样本量和计算量大,样本数目较多时候不建议使用。
判别模型优点:1)计算和样本数量少。
2)准确率高。
缺点:收敛慢,不能针对隐变量。
. 8.4
. ROC曲线
ROC曲线又叫接受者操作特征曲线,比较学习器模型好坏可视化工具,横坐标参数假正例率,纵坐标参数是真正例率。
曲线越靠近对角线(随机猜测线)模型越不好。
好的模型,真正比例比较多,曲线应是陡峭的从0开始上升,后来遇到真正比例越来越少,假正比例元组越来越多,曲线平缓变的更加水平。
完全正确的模型面积为1
9 统计学知识
信息图形化(饼图,线形图等)
集中趋势度量(平均值 中位数 众数 方差等)
概率
排列组合
分布(几何二项泊松正态卡方)
统计抽样
样本估计
假设检验
回归
10 stanfordNLP
句子理解、自动问答系统、机器翻译、句法分析、标注、情感分析、文本和视觉场景和模型, 以及自然语言处理数字人文社会科学中的应用和计算。
11 APache OpenNLP
Apache的OpenNLP库是自然语言文本的处理基于机器学习的工具包。
它支持最常见的NLP任务,如断词,句子切分,部分词性标注,命名实体提取,分块,解析和指代消解。
句子探测器:句子检测器是用于检测句子边界
标记生成器:该OpenNLP断词段输入字符序列为标记。
常是这是由空格分隔的单词,但也有例外。
名称搜索:名称查找器可检测文本命名实体和数字。
POS标注器:该OpenNLP POS标注器使用的概率模型来预测正确的POS标记出了标签组。
细节化:文本分块由除以单词句法相关部分,如名词基,动词基的文字,但没有指定其内部结构,也没有其在主句作用。
分析器:尝试解析器最简单的方法是在命令行工具。
该工具仅用于演示和测试。
请从我们网站上的英文分块
12 Lucene
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Lucene 目前是 Apache Jakarta(雅加达) 家族中的一个 开源项目。
也是目前最为流行的基于Java开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于 Lucene ,比如Eclipse 帮助系统的搜索功能。
Lucene能够为文本类型的数 据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
13 Apache Solr
Solr它是一种开放源码的、基于 Lucene Java 的搜索服务器。
Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式。
它易于安装和配置, 而且附带了一个基于HTTP 的管理界面。
可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。
Solr的特性包括:
•高级的全文搜索功能
•专为高通量的网络流量进行的优化
•基于开放接口(XML和HTTP)的标准
•综合的HTML管理界面
•可伸缩性-能够有效地复制到另外一个Solr搜索服务器
•使用XML配置达到灵活性和适配性
•可扩展的插件体系 solr中文分词
14 机器学习降维
主要特征选取、随机森林、主成分分析、线性降维
15 领域本体构建方法
1 确定领域本体的专业领域和范畴
2 考虑复用现有的本体
3 列出本体涉及领域中的重要术语
4 定义分类概念和概念分类层次
5 定义概念之间的关系
16 构建领域本体的知识工程方法:
主要特点:本体更强调共享、重用,可以为不同系统提供一种统一的语言,因此本体构建的工程性更为明显。
方法:目前为止,本体工程中比较有名的几种方法包括TOVE 法、Methontology方法、骨架法、IDEF-5法和七步法等。
(大多是手工构建领域本体)
现状: 由于本体工程到目前为止仍处于相对不成熟的阶段,领域本体的建设还处于探索期,因此构建过程中还存在着很多问题。
方法成熟度: 以上常用方法的依次为:七步法、Methontology方法、IDEF-5法、TOVE法、骨架法。
17 特征工程
. 1 特征工程是什么?
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。
通过总结和归纳,人们认为特征工程包括以下方面:
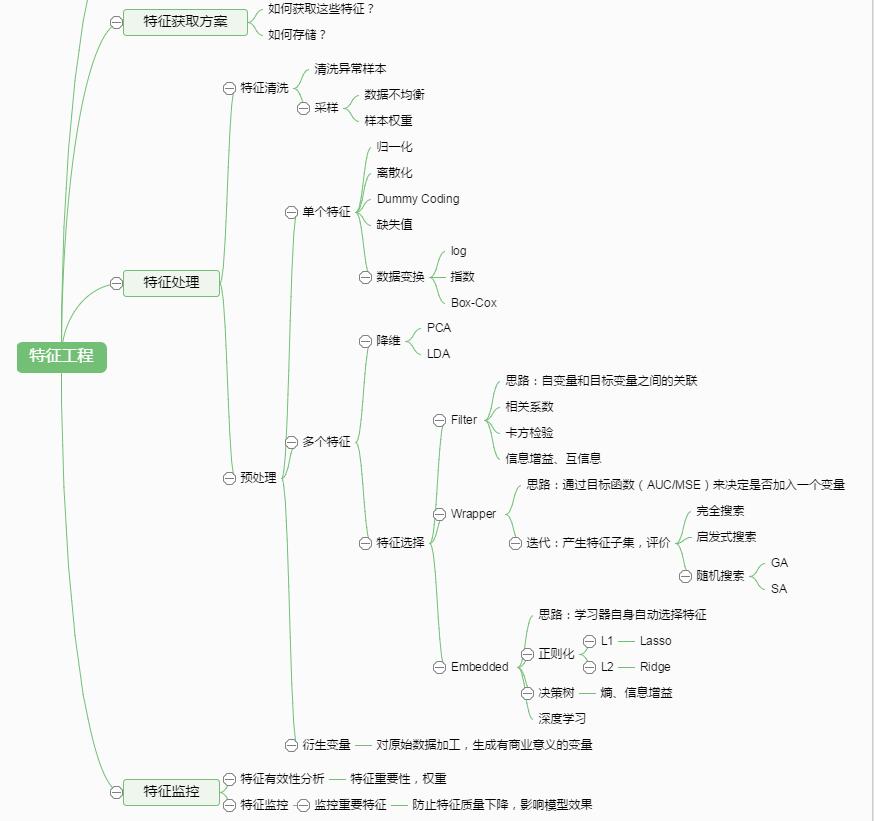 特征处理是特征工程的核心部分,特征处理方法包括数据预处理,特征选择,降维等。
. 2 特征提取:特征提取是指将机器学习算法不能识别的原始数据转化为算法可以识别的特征的过程。
. 实例解析:文本是由一系列文字组成的,这些文字在经过分词后会形成一个词语集合,对于这些词语集合(原始数据),机器学习算法是不能直接使用的,我们需要将它们转化成机器学习算法可以识别的数值特征(固定长度的向量表示),然后再交给机器学习的算法进行操作。
再比如说,图片是由一系列像素点构(原始数据)成的,这些像素点本身无法被机器学习算法直接使用,但是如果将这些像素点转化成矩阵的形式(数值特征),那么机器学习算法就可以使用了。
特征提取实际上是把原始数据转化为机器学习算法可以识别的数值特征的过程,不存在降维的概念,特征提取不需要理会这些特征是否是有用的;而特征选择是在提取出来的特征中选择最优的一个特征子集。
. 文本分类特征提取步骤:
假设一个语料库里包含了很多文章,在对每篇文章作了分词之后,可以把每篇文章看作词语的集合。
然后将每篇文章作为数据来训练分类模型,但是这些原始数据是一些词语并且每篇文章词语个数不一样,无法直接被机器学习算法所使用,机器学习算法需要的是定长的数值化的特征。
因此,我们要做的就是把这些原始数据数值化,这就对应了特征提取。
如何做呢?
对训练数据集的每篇文章,我们进行词语的统计,以形成一个词典向量。
词典向量里包含了训练数据里的所有词语(假设停用词已去除),且每个词语代表词典向量中的一个元素。
在经过第一步的处理后,每篇文章都可以用词典向量来表示。
这样一来,每篇文章都可以被看作是元素相同且长度相同的向量,不同的文章具有不同的向量值。
这也就是表示文本的词袋模型(bag of words)。
针对于特定的文章,如何给表示它的向量的每一个元素赋值呢?最简单直接的办法就是0-1法了。
简单来说,对于每一篇文章,我们扫描它的词语集合,如果某一个词语出现在了词典中,那么该词语在词典向量中对应的元素置为1,否则为0。
在经过上面三步之后,特征提取就完成了。
对于每一篇文章,其中必然包含了大量无关的特征,而如何去除这些无关的特征,就是特征选择要做的事情了。
. 3 数据预处理:未经处理的特征,这时的特征可能有以下问题:(标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布)
特征的规格不一样。
无量纲化可以解决。
信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。
二值化可以解决这一问题。
定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。
假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。
存在缺失值:缺失值需要补充。
信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的。
使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
. 4 特征选择:当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。
特征选择是指去掉无关特征,保留相关特征的过程,也可以认为是从所有的特征中选择一个最好的特征子集。
特征选择本质上可以认为是降维的过程。
. 1)Filter(过滤法):按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
如:方差选择法、相关系数法、卡方检验法、互信息法
. 方差选择法:使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
. 相关系数法:使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。
. 卡方检验法:经典的卡方检验是检验定性自变量对定性因变量的相关性。
假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量。
. 互信息法: 经典的互信息也是评价定性自变量对定性因变量的相关性的。
. 2)Wrapper(包装法):根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
如:递归特征消除法
. 递归特征消除法:递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
. 3)Embedded(嵌入法):先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
类似于Filter方法,但是是通过训练来确定特征的优劣。
. 基于惩罚项的特征选择法:使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。
使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型。
如:基于惩罚项的特征选择法、基于树模型的特征选择法
. 基于树模型的特征选择法:树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型。
. 4)深度学习方法:从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。
. 5 降维:当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。
常见的降维方法:L1惩罚项的模型、主成分分析法(PCA)、线性判别分析(LDA)。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中。
所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
. 1)主成分分析法(PCA):使用decomposition库的PCA类选择特征。
. 2)线性判别分析法(LDA):使用lda库的LDA类选择特征。
特征处理是特征工程的核心部分,特征处理方法包括数据预处理,特征选择,降维等。
. 2 特征提取:特征提取是指将机器学习算法不能识别的原始数据转化为算法可以识别的特征的过程。
. 实例解析:文本是由一系列文字组成的,这些文字在经过分词后会形成一个词语集合,对于这些词语集合(原始数据),机器学习算法是不能直接使用的,我们需要将它们转化成机器学习算法可以识别的数值特征(固定长度的向量表示),然后再交给机器学习的算法进行操作。
再比如说,图片是由一系列像素点构(原始数据)成的,这些像素点本身无法被机器学习算法直接使用,但是如果将这些像素点转化成矩阵的形式(数值特征),那么机器学习算法就可以使用了。
特征提取实际上是把原始数据转化为机器学习算法可以识别的数值特征的过程,不存在降维的概念,特征提取不需要理会这些特征是否是有用的;而特征选择是在提取出来的特征中选择最优的一个特征子集。
. 文本分类特征提取步骤:
假设一个语料库里包含了很多文章,在对每篇文章作了分词之后,可以把每篇文章看作词语的集合。
然后将每篇文章作为数据来训练分类模型,但是这些原始数据是一些词语并且每篇文章词语个数不一样,无法直接被机器学习算法所使用,机器学习算法需要的是定长的数值化的特征。
因此,我们要做的就是把这些原始数据数值化,这就对应了特征提取。
如何做呢?
对训练数据集的每篇文章,我们进行词语的统计,以形成一个词典向量。
词典向量里包含了训练数据里的所有词语(假设停用词已去除),且每个词语代表词典向量中的一个元素。
在经过第一步的处理后,每篇文章都可以用词典向量来表示。
这样一来,每篇文章都可以被看作是元素相同且长度相同的向量,不同的文章具有不同的向量值。
这也就是表示文本的词袋模型(bag of words)。
针对于特定的文章,如何给表示它的向量的每一个元素赋值呢?最简单直接的办法就是0-1法了。
简单来说,对于每一篇文章,我们扫描它的词语集合,如果某一个词语出现在了词典中,那么该词语在词典向量中对应的元素置为1,否则为0。
在经过上面三步之后,特征提取就完成了。
对于每一篇文章,其中必然包含了大量无关的特征,而如何去除这些无关的特征,就是特征选择要做的事情了。
. 3 数据预处理:未经处理的特征,这时的特征可能有以下问题:(标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布)
特征的规格不一样。
无量纲化可以解决。
信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。
二值化可以解决这一问题。
定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。
假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。
存在缺失值:缺失值需要补充。
信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的。
使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
. 4 特征选择:当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。
特征选择是指去掉无关特征,保留相关特征的过程,也可以认为是从所有的特征中选择一个最好的特征子集。
特征选择本质上可以认为是降维的过程。
. 1)Filter(过滤法):按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
如:方差选择法、相关系数法、卡方检验法、互信息法
. 方差选择法:使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
. 相关系数法:使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。
. 卡方检验法:经典的卡方检验是检验定性自变量对定性因变量的相关性。
假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量。
. 互信息法: 经典的互信息也是评价定性自变量对定性因变量的相关性的。
. 2)Wrapper(包装法):根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
如:递归特征消除法
. 递归特征消除法:递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
. 3)Embedded(嵌入法):先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
类似于Filter方法,但是是通过训练来确定特征的优劣。
. 基于惩罚项的特征选择法:使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。
使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型。
如:基于惩罚项的特征选择法、基于树模型的特征选择法
. 基于树模型的特征选择法:树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型。
. 4)深度学习方法:从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。
. 5 降维:当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。
常见的降维方法:L1惩罚项的模型、主成分分析法(PCA)、线性判别分析(LDA)。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中。
所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
. 1)主成分分析法(PCA):使用decomposition库的PCA类选择特征。
. 2)线性判别分析法(LDA):使用lda库的LDA类选择特征。
18 模型评估之交叉验证
k折交叉验证(k-fold cross-validation)用一部分数据来训练模型,然后用另一部分数据来测试模型的泛化误差。
该算法的具体步骤如下:
随机将训练样本等分成k份。
对于每一份验证数据Sj,算法在S1, …, SJ-1, SJ+1, …, Sk上进行特征选择,并且构造文本分类器。
把得到的文本分类器在验证集Sj上求泛化误差。
把k个泛化误差求平均,得到最后的泛化误差。
19 EM算法
EM算法:当模型里含有隐变量的时候,直接求解参数的极大似然估计就会失效。
这时就需要用到来对参数进行迭代求解。
EM算法说白了也是求含有隐变量的参数的极大似然估计。
常用于混合模型(高斯混合模型,伯努利混合模型),训练推理主题模型(topic model)时的pSLA等等。
EM算法步骤:给定可观测变量的集合为X,隐藏变量的集合为Z,模型参数用W的联合概率分布,即,p(X,Z|W),目标是要最大化似然函数p(X|W),也就是要求出W使得p(X|W)最大。
选择参数W的初始值,Wold即隐变量Z的后验概率,即p(Z|X,Wold)
E步:利用初始值Wold计算隐变量Z的后验概率分布,p(Z|X,Wold),进而找出logp(X,Z|W)在Z的后验概率下的期望Q(W,Wold)。
M步:极大化Q(W,Wold),以求出W。
检查收敛条件,如果满足收敛条件则停止;否则,令Wold= Wnew,然后跳转到第2步,继续迭代执行。
20、推荐算法
推荐算法通常是在推荐模型中实现的,而推荐模型会负责收集诸如用户偏好、物品描述这些可用作推荐凭借的数据,据此预测特定用户组可能感兴趣的物品。
1、基于协同过滤算法:
原理:用户行为中寻找特定模式,创建用户专属的推荐内容。
例子:你的朋友喜欢电影哈利波特I,那么就会推荐给你,这是最简单的基于用户的协同过滤算法,还有一种是基于Item的协同过滤算法,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
输入内容:只取决于使用数据(评价、购买、下载、用户偏好)
类型:基于相似类型的协同
过滤(比如基于兴趣类似的用户或者基于类似的物品) 基于模型的协同过滤
<-----基于用户的协同过滤案例--->
假设我们有一些用户已经表达了他们对某些书籍的偏好,他们越喜欢某本书,对这本书的评分也越高(评分范围是1分到5分)。
我们可以在一个矩阵中重现他们的这种偏好,用行代表用户,用列代表书籍。
在基于用户的协同过滤算法中,我们要做的第一件事就是根据用户对书籍的偏好,计算出他们彼此间的相似度。
我们从某个单独用户的角度来看一下这个问题,以图一中第一行的用户为例。
通常我们会将每个用户都作为向量(或者数组),其中包含了用户对物品的偏好
。
通过多种类似的指标对用户进行对比是相当直接的。
在本例中,我们会使用余弦相似点。
我们将第一位用户与其他五位相对比,可以发现第一位与其他用户的相似度有多少(第一位用户与其他用户的相似性。
可以在一个单独的维度中绘制用户间的余弦相似性。
)。
就
像大多相似度指标一样,向量之间的相似度越高,彼此也就越相似。
在本例中,第一位用户与其中两位有两本相同的书籍,相似度较高;与另两位只有一本相同书籍,相似度较低;与最后一位没有相同书籍,相似度为零。
更常见的情况下,我们可以计算出每名用户与所有用户的相似程度,并在相似性矩阵中表现出来(用户间的相似矩阵,每个用户的相似度是基于用户阅读书籍间的相似性。
)。
这是一个对称矩阵,也就是说其中一些有用的属性是可以执行数学函数运算的。
单元格的背景
色表明了用户彼此间的相似程度,红色越深则相似度越高。
现在,我们准备使用基于用户的协同过滤来生成给用户的推荐。
对于特定的用户来说,这代表着找出与其相似性最高的用户,并根据这些类似用户喜爱的物品进行推荐,具体要参照用户相似程度来加权。
我们先以第一个用户为例,为其生成一些推荐。
首先我们找到与这
名用户相似程度最高的n名用户,删除这名用户已经喜欢过的书籍,再对最相似用户阅读过的书籍进行加权,之后将所有结果加在一起。
在本例中,我们假设n=2,也就是说取两名与第一位用户最相似的用户,以生成推荐结果,这两名用户分别是用户2及用户3(图四)。
由于第一名用户已经对书籍1和书籍5做出了评分,推荐结果生成书籍3(分数4.5)及书籍4(分数3)。
基于用户的CF:
1、分析各个用户对item的评价(通过浏览记录、购买记录等);
2、依据用户对item的评价计算得出所有用户之间的相似度;
3、选出与当前用户最相似的N个用户;
4、将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。
最后,我们要为用户1推荐物品,则找出与用户1相似度最高的N名用户(设N=2)评价的物品,去掉用户1评价过的物品,则是推荐结果。
<-------基于物品的协同过滤的案例------>
我们还是用同一组用户(图一)为例。
在基于物品的协同过滤中,与基于用户的协同过滤类似,我们要做的第一件事就是计算相似度矩阵。
但这一回,我们想要针对物品而非用户来看看它们之间的相似性。
与之前类似,我们以书籍作为喜爱者的向量(或数组),将其与
余弦相似度函数相对比,从而揭示出某本书籍与其他书籍之间的相似程度。
由于同一组用户给出的评分大致类似,位于列1的第一本书与位于列5的第五本书相似度是最高的(图五)。
其次是相似度排名第三的书籍,有两位相同的用户喜爱;排名第四和第二的书籍只有一
位共同读者;而排名最后的书籍由于没有共同读者,相似度为零。
我们还可以在相似矩阵中展示出所有书籍彼此间的相似程度(图六)。
同样以背景颜色区分了两本书彼此间的相似程度,红色越深相似程度也越高。
现在我们知道每本书彼此间的相似程度了,可以为用户生成推荐结果。
在基于物品的协同过滤中,我们根据用户此前曾评过分的物品,推荐与其最为相似的物品。
在案例中,第一位用户获得的推荐结果为第三本书籍,然后是第六本(图七)。
同样地,我们只取与用户之
前评论过的书籍最相似的两本书。
根据上述描述,基于用户与基于物品的协同过滤似乎非常类似,因此能得出不同的结果这一点确实很有意思。
即便在上例中,这两种方式都能为同一名用户得出不同的推荐结果,尽管两者的输入内容是相同的。
在构建推荐时,这两种形式的协同过滤方式都是值得考虑的
。
尽管在向外行描述时,这两种方法看起来非常类似,但实际上它们能得出非常不同的推荐结果,从而为用户带来完全不同的体验。
根据上述核心思想,可以有如下算法步骤:
建立用户-物品的倒排表
物品与物品之间的共现矩阵 C[i][j],表示物品 i 与 j 共同被多少用户所喜欢。
用户与用户之间的相似度矩阵 W[i][j] , 根据余弦相似度计算公式计算。
用上面的相似度矩阵来给用户推荐与他所喜欢的物品相似的其他物品。
用户 u 对物品 j 的兴趣程度可以估计为
UserCF 和 ItemCF 的区别和应用
UserCF 算法的特点是:
用户较少的场合,否则用户相似度矩阵计算代价很大
适合时效性较强,用户个性化兴趣不太明显的领域
对新用户不友好,对新物品友好,因为用户相似度矩阵不能实时计算
很难提供令用户信服的推荐解释
对应地,ItemCF 算法的特点:
适用于物品数明显小于用户数的场合,否则物品相似度矩阵计算代价很大
适合长尾物品丰富,用户个性化需求强的领域
对新用户友好,对新物品不友好,因为物品相似度矩阵不需要很强的实时性(cosα=(A*B)/(||A||*||B||))
利用用户历史行为做推荐解释,比较令用户信服
因此,可以看出 UserCF 适用于物品增长很快,实时性较高的场合,比如新闻推荐。
而在图书、电子商务和电影领域,比如京东、天猫、优酷中,ItemCF 则能极大地发挥优势。
在这些网站中,用户的兴趣是比较固定和持久的,而且这些网站的物品更新速度不会特别快,
一天一更新是在忍受范围内的。
模型评价指标:准确率、召回率、覆盖率、新颖性、惊喜度、实时性
2、基于内容过滤的推荐算法
原理:用户喜欢和自己关注过的Item在内容上类似的Item。
例子:你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你,这种方法可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是
基于内容的推荐算法可以分析Item之间的关系,实现推荐),
缺点:①推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的,内容一致;②对于一些多媒体的推荐(比如音乐、电影、图片等)由于很难提内容特征,则很难进行推荐,一种解决方式则是人工给这些Item打
标签。
输入内容:取决于物品及用户的内容/描述
3、混合型推荐算法
原理:结合协同过滤和基于内容两种方式,以利用某个算法优点解决另一个的缺点
输入内容:通过用户/物品内容特征及使用数据以借助两类数据的优势
4、流行度推荐算法
原理:根据流行度来推荐物品的算法(比如下载、观看、影响度较高的)
输入内容:通过使用数据与物品内容(比如分类)